How I took down my site and then fixed it with MemoLock.
Cache is money. Don't work hard just because your cache expired.

TL;DR
When you do simple reads/writes to a cache, you risk having a ton of database queries when your cache expires (which can have disastrous effects). With MemoLock, only one process fetches while every other process waits. You can find a Redis MemoLock implementation for C# and Go here, and my Node/TypeScript implementation (which is fully tested and used in production) here.
Story Time
The website I work on allows users to join a queue.
Initially, when a user loaded the "queue page", we fetched how many users were in the queue:
SELECT count(*) FROM que_user WHERE "queId" = $1 AND "status" < $2
O(n) latency is manageable, since when you 4x your load, things slow down 4x, and you have time to improve it. However, when latency becomes O(n^2) (4x load -> 16x latency), issues can arise seemingly overnight.
One day...
One day, we had 5,500 users in the queue. Yay! Everything leading up to the event seems fine. We're only able to take a limited number of users from the queue at a time (let's say 500), so the event starts and 500 users are taken in the first wave. This is where things go wrong.
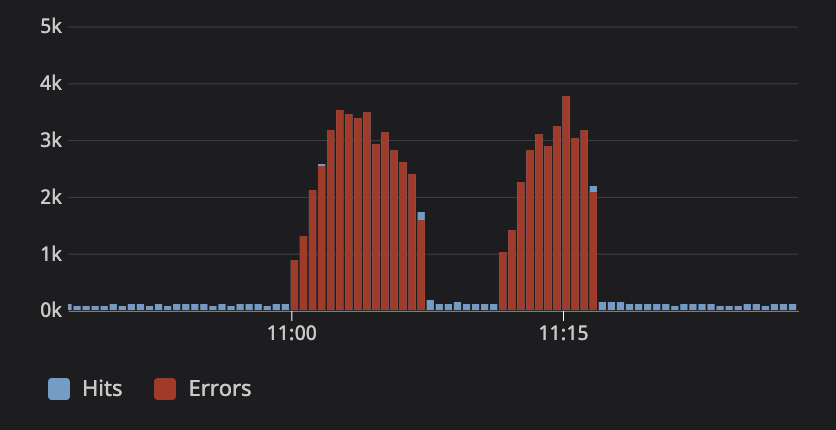
Nothing is loading. Whether it be because users are confused that they weren't in the first wave or something else, users begin to reload the page. I might not have noticed this before because, if this happens with 1,000 users, each request only counts 1,000 rows in the database. Postgres seemed to manage counting 1M total rows just fine. With 5,000, that's counting ~25M rows. Database is not happy. Query timeouts everywhere. People refresh multiple times because things aren't loading. Load increases even more.
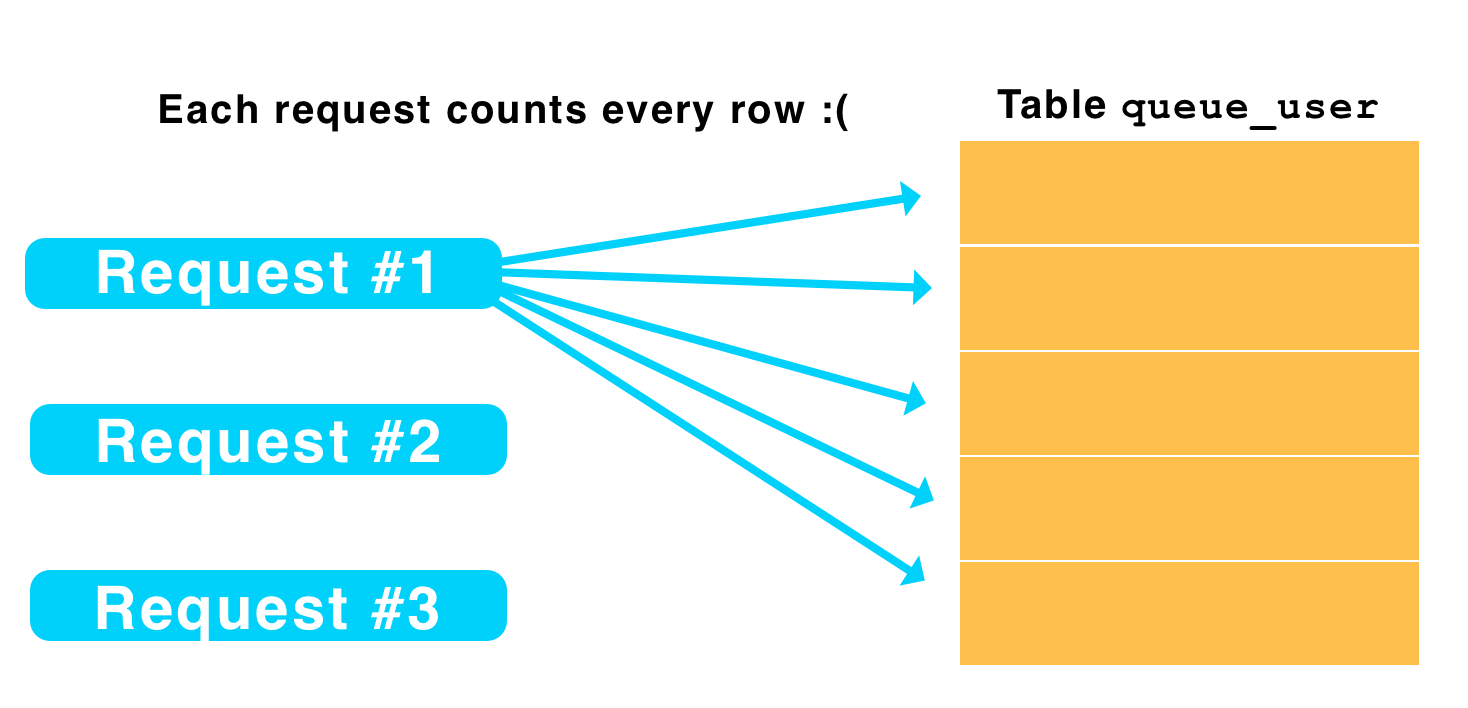
Just cache it... right?
Indeed, the immediate solution is to cache. After I discovered the root cause, I added a cache with a 2 second expiration. Users might not get the exact count, but it won't be off by very much. (This could be improved by incrementing/decrementing the cache when a user joins or leaves to make it more accurate.)
This does technically have a race condition where there will be multiple requests when the cache expires. That's not a big deal, so long as we're fast enough to populate the cache... But what if another query slows down the database?
A couple months later
On one fateful day, another query causes high database load. Our "count query" starts timing out, but that means the cache is never populated. Suddenly, we're making even more database requests than before, which only contributes to the problem.
Memolock
The answer is memolock. Redis and Instagram have both written articles regarding this issue. The solution is rather simple: One process fetches, and everybody else waits for the cache to be populated. When things get slow, only one SQL request will go through at a time. The actual implementation is trickier because you need to handle locks timing out, processes crashing, and missed Redis pub/sub messages.
Luckily, some libraries exist. You can find an implementation with Redis for C# and Go here, and my Node/TypeScript implementation (which is fully tested and used in production) here.
 Cache all the things. Then cache harder.
Cache all the things. Then cache harder.
Conclusion
That's MemoLock, the next step on your caching journey. With a library, you don't even need to think about the locking. The overhead is low, so even if you don't need it, you're only making a couple additional Redis queries when populating the cache. If you do need it... you might be sorry that you don't have it.
import MemolockCache from 'redis-memolock';
const cache = new MemolockCache();
function getUsersInQueCount(queId: string) {
return cache.get(
// Key
'que-user-count:' + queId,
// Cache for 5 seconds
{ ttlMs: 5 * 1000 },
// When not cached, count # of users in a
// queue with a database query.
() => countQuersWithDb(queId),
);
}